马上注册,结交更多好友,享用更多功能,让你轻松玩转社区。
您需要 登录 才可以下载或查看,没有账号?立即注册
x
DeepSeek 正式启动了其「开源周」发布计划,并在首日开源了 MLA 解码内核 FlashMLA。

FlashMLA 发布后,沐曦技术团队迅速响应,在开源当天完成了与沐曦 GPU 的适配工作,并将代码上传至 Gitee:https://gitee.com/metax-maca/FlashMLA。这使得沐曦 GPU 成为首个适配 DeepSeek FlashMLA 的国产芯片!

FlashMLA:加速 MLA 推断解码 MLA(Multi-Head Latent Attention)是一种用于深度学习模型的注意力机制,旨在提高模型对输入信息的处理效率和表达能力。 它的设计思想是通过低秩联合压缩技术,减少了推理时的键值(KV)缓存,从而在保持性能的同时显著降低了内存占用,进而增强模型的表达能力。

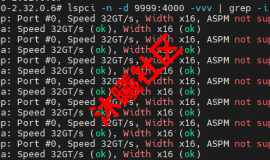
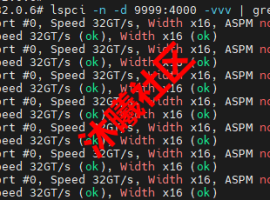
MLA 流程图 本次开源的 FlashMLA 一方面继承了 MLA 的思想,另一方面也受到了另一种注意力机制 Flash Attention 的启发,有效加速大语言模型的解码过程。这对提升聊天机器人等实时生成场景中的响应速度和吞吐量具有重要意义。 不仅是快速适配,更是架构突破 沐曦团队在适配过程中不仅支持了 FlashMLA 的性能要求,还通过矩阵吸收算法将低秩投影融入 Flash Attention 2 核函数,在保证计算效率的同时显著减少显存占用。这一优化对显存敏感场景,特别是长文本生成任务,提供了显著的性能增益。 值得一提的是,沐曦此次提交的代码还突破了官方实现中对 Hopper 架构的依赖,并新增了对64以外多样化 page size 配置的支持,进一步提升了框架的适用性。 本次适配成功后,沐曦 MXMACA 平台也可完美运行 FlashMLA,这充分验证了沐曦 GPGPU 架构与 MXMACA 软件平台在生态兼容性方面的先天优势。 在本次适配工作中,沐曦 GPU 在加速大语言模型推断解码及优化显存使用方面表现出色,充分证明了国产芯片在全球 智算生态中的竞争力。
| 







 社区规则
社区规则 隐私保护
隐私保护 监督机制
监督机制 关于版权
关于版权