马上注册,结交更多好友,享用更多功能,让你轻松玩转社区。
您需要 登录 才可以下载或查看,没有账号?立即注册
x
INFO 05-26 15:43:28 [__init__.py:243] No platform detected, vLLM is running on UnspecifiedPlatform
WARNING 05-26 15:43:29 [_custom_ops.py:21] Failed to import from vllm._C with ImportError('libcuda.so.1: cannot open shared object file: No such file or directory')
Namespace(backend='vllm', dataset=None, input_len=512, output_len=512, n=1, num_prompts=64, hf_max_batch_size=None, output_json=None, async_engine=False, disable_frontend_multiprocessing=False, lora_path=None, model='/model/Qwen/Qwen2.5-7B-Instruct/', task='auto', tokenizer='/model/Qwen/Qwen2.5-7B-Instruct/', hf_config_path=None, skip_tokenizer_init=False, revision=None, code_revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=False, allowed_local_media_path=None, load_format='auto', download_dir=None, model_loader_extra_config={}, use_tqdm_on_load=True, config_format=<ConfigFormat.AUTO: 'auto'>, dtype='bfloat16', max_model_len=None, guided_decoding_backend='auto', reasoning_parser=None, logits_processor_pattern=None, model_impl='auto', distributed_executor_backend=None, pipeline_parallel_size=1, tensor_parallel_size=1, data_parallel_size=1, enable_expert_parallel=False, max_parallel_loading_workers=None, ray_workers_use_nsight=False, disable_custom_all_reduce=False, block_size=None, gpu_memory_utilization=0.9, swap_space=4, kv_cache_dtype='auto', num_gpu_blocks_override=None, enable_prefix_caching=None, prefix_caching_hash_algo='builtin', cpu_offload_gb=0, calculate_kv_scales=False, disable_sliding_window=False, use_v2_block_manager=True, seed=None, max_logprobs=20, disable_log_stats=False, quantization=None, rope_scaling=None, rope_theta=None, hf_token=None, hf_overrides=None, enforce_eager=False, max_seq_len_to_capture=8192, tokenizer_pool_size=0, tokenizer_pool_type='ray', tokenizer_pool_extra_config={}, limit_mm_per_prompt={}, mm_processor_kwargs=None, disable_mm_preprocessor_cache=False, enable_lora=None, enable_lora_bias=False, max_loras=1, max_lora_rank=16, lora_extra_vocab_size=256, lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=None, fully_sharded_loras=False, enable_prompt_adapter=None, max_prompt_adapters=1, max_prompt_adapter_token=0, device='auto', speculative_config=None, ignore_patterns=[], served_model_name=None, qlora_adapter_name_or_path=None, show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, disable_async_output_proc=False, max_num_batched_tokens=None, max_num_seqs=None, max_num_partial_prefills=1, max_long_partial_prefills=1, long_prefill_token_threshold=0, num_lookahead_slots=0, scheduler_delay_factor=0.0, preemption_mode=None, num_scheduler_steps=1, multi_step_stream_outputs=True, scheduling_policy='fcfs', enable_chunked_prefill=None, disable_chunked_mm_input=False, scheduler_cls='vllm.core.scheduler.Scheduler', override_neuron_config=None, override_pooler_config=None, compilation_config=None, kv_transfer_config=None, worker_cls='auto', worker_extension_cls='', generation_config='auto', override_generation_config=None, enable_sleep_mode=False, additional_config=None, enable_reasoning=False, disable_cascade_attn=False, disable_log_requests=False)
Traceback (most recent call last):
File "/model/vllm/benchmarks/benchmark_throughput.py", line 531, in <module>
main(args)
File "/model/vllm/benchmarks/benchmark_throughput.py", line 402, in main
elapsed_time = run_vllm(requests, args.n,
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/model/vllm/benchmarks/benchmark_throughput.py", line 170, in run_vllm
llm = LLM(**dataclasses.asdict(engine_args))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/vllm/lib/python3.12/site-packages/vllm/utils.py", line 1161, in inner
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/vllm/lib/python3.12/site-packages/vllm/entrypoints/llm.py", line 247, in __init__
self.llm_engine = LLMEngine.from_engine_args(
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/vllm/lib/python3.12/site-packages/vllm/engine/llm_engine.py", line 503, in from_engine_args
vllm_config = engine_args.create_engine_config(usage_context)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/vllm/lib/python3.12/site-packages/vllm/engine/arg_utils.py", line 1098, in create_engine_config
device_config = DeviceConfig(device=self.device)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<string>", line 4, in __init__
File "/root/miniconda3/envs/vllm/lib/python3.12/site-packages/vllm/config.py", line 2119, in __post_init__
raise RuntimeError(
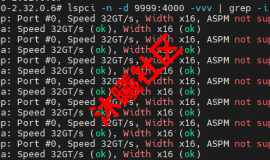
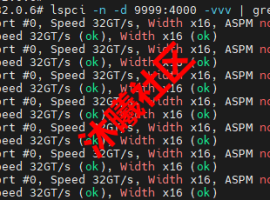
RuntimeError: Failed to infer device type, please set the environment variable `VLLM_LOGGING_LEVEL=DEBUG` to turn on verbose logging to help debug the issue.
|







 社区规则
社区规则 隐私保护
隐私保护 监督机制
监督机制 关于版权
关于版权