马上注册,结交更多好友,享用更多功能,让你轻松玩转社区。
您需要 登录 才可以下载或查看,没有账号?立即注册
x
本帖最后由 fsword73 于 2025-4-16 10:31 编辑
原始文章请参考:
godweiyang:PyTorch自定义CUDA算子教程与运行时间分析
实际上该文章对应有三个方法:godweiyang:详解PyTorch编译并调用自定义CUDA算子的三种方式
- a) 使用JIT方式调用和编译CUDA算子;
- b) setup方法
- c) 使用CMAKE
我们先来阅读一下godweiyang的源代码:
源代码部分:(1) GPU kernel和 CPU function call
__global__ void add2_kernel(float* c, const float* a, const float* b,int n)
{
for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < n; i += gridDim.x * blockDim.x) {
c = a + b; }
}
void launch_add2(float* c, const float* a, const float* b,int n) {
dim3 grid((n + 1023) / 1024);
dim3 block(1024);
add2_kernel<<<grid, block>>>(c, a, b, n);
}
源代码部分: (2)pytorch tensor 绑定及动态库
#include <torch/extension.h>
#include "add2.h"
void torch_launch_add2(torch::Tensor &c, const torch::Tensor &a, const torch::Tensor &b,int64_t n) {
launch_add2((float *)c.data_ptr(), (const float *)a.data_ptr(), (const float *)b.data_ptr(), n);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("torch_launch_add2",
&torch_launch_add2,
"add2 kernel warpper");
}
TORCH_LIBRARY(add2, m) {
m.def("torch_launch_add2",
torch_launch_add2);
}
源代码部分: (3)pytorch JIT 编译过程,并加载pytorch extension
if args.compiler == 'jit':
from torch.utils.cpp_extension import load
cuda_module = load(name="add2",
extra_include_paths=["include"],
sources=["pytorch/add2_ops.cpp", "kernel/add2_kernel.cu"],
verbose=True)
源代码部分(4):调用pytorch extension的CUDA模块
cuda_module.torch_launch_add2(cuda_c, a, b, n)
下面在MACA平台上重复该文章
复现步骤一:下载源代码
git clone https://githubfast.com/godweiyang/torch-cuda-example.git
步骤二:查看GPU及pytorch信息。
[backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
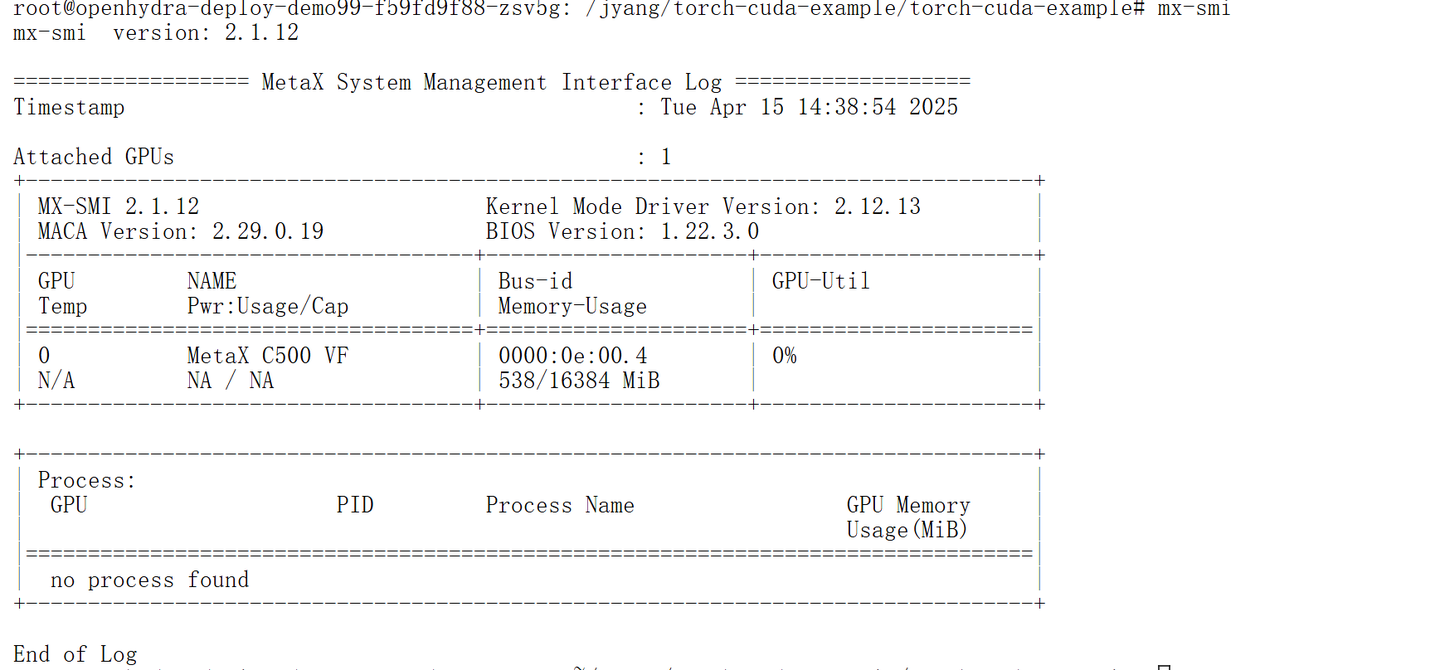
MX-SMI查看曦云 GPU信息
MX-SMI获得如下信息:
MACA Version : 2.29.0.19
GPU是曦云系列GPU的一个虚拟机,虚拟机配置了16GB的GPU显存。
执行"pip list"命令获取pytorch是否安装,
[backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
pip list命令的部分截图
torch版本是torch2.1.2。比较有趣的是,对应的MACA版本号是2.29.0.4,低于系统安装的SDK版本。
步骤三: 测试MACA SDK下pytorhc 调用 JIT方式的CUDA
[backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
三步编译源代码
可以看到JIT分三步编译源代码,分别产生 gpu kernel 对应的add2_kernel.cuda.o 和 CPU function add2_op.o和最后link产生的add2.so三个文件。
0代码修改直接通过,0成本迁移。
讨论: pytorch+JIT + CUDA算子的价值在哪里?
- 用户自定义算子的简单测试框架;不用编写复杂的测试程序,快速调优;
- 用户自定义算子的快速实现,和pytorch框架快速融合,不需要二次编译pytorch;加速应用落地;
- 当用户自定义算子很多的时候,使用setup或cmake来实现,这是许多pytorch扩展特定领域应用的一种方式,例如蛋白质,CAD,流体力学,化学等
|


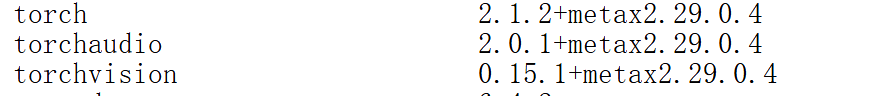



 赞
赞




 社区规则
社区规则 隐私保护
隐私保护 监督机制
监督机制 关于版权
关于版权